Predictive Modeling and Machine Learning: Sharpening the Focus of Real-World Evidence in the Age of Precision Medicine
April 17, 2020

The challenge of real-world evidence in the age of precision medicine
Real-world evidence is being used increasingly to provide important information about natural history of a disease, drug utilization and treatment patterns, comorbidities, safety and effectiveness of medications, along with healthcare utilization, cost of care, and other economic analyses. Administrative databases are a cornerstone of real-world evidence, offering real-time data for large populations in which to study rare diseases and sensitive subgroups. While bringing unparalleled scope, large claims databases can lack the clinical depth needed to address certain challenges, while Electronic Medical Records databases can have significant missing data limitations.
Rapid advances in precision medicine are revealing many diseases to be heterogeneous entities with different etiologies and natural histories. This understanding is opening doors for the development of more effective targeted treatments. For example, over the past decade, breast cancer therapies have been approved for and successfully treated specific forms of the disease defined by molecular profiling. As targeted treatments proliferate, there is a growing need to better understand smaller subpopulations with more narrowly defined conditions of interest. Administrative claims databases contain longitudinal healthcare information on all billed healthcare encounters on the scale needed to effectively study targeted indications.
Rapidly evolving coding systems contain a plethora of diagnosis codes, yet lag the development of clinical information like staging, and molecular and genomic profiling. This situation presents a challenge to researchers trying to unlock the potential of automated databases to support the moving target of therapeutic advances.
Addressing the inaccuracy of diagnosis codes
Researchers have learned that patterns of care defined by combinations of diagnosis, procedure, and treatment codes in claims can identify people with health conditions of interest more accurately than is possible using diagnosis codes alone. These algorithms take the form of Boolean expressions with multiple codes included and a dichotomous outcome (if this AND not that, OR this, THEN case=yes). Usually codes are selected based on prior knowledge by clinicians with experience diagnosing the condition. Validation studies have shown that conventional algorithms often do not perform well, however, so there is a need for methodologies that can improve algorithm performance.
Formal statistical methods offer several strategies that can improve accuracy of case identification. Multivariate prediction models such as logistic regression models can estimate the probability of being a case as a continuous outcome instead of a binary outcome. In addition, predictors are not simply included in the algorithm as binary variables, rather they can have continuous coefficients depending on the strength of their relation to the outcome. Further, instead of relying solely on prior knowledge, models can use relationships in the validation data to select predictors and estimate the degree to which they are associated with the outcome. Using the validation study data to develop the model presents a risk of overfitting, in which the model is influenced by chance associations in the sample data that do not apply outside the sample. To avoid overfitting, validation samples can be split in two so that the model is developed using a training data set and model performance is assessed using a testing data set. To reduce the loss of efficiency introduced by splitting the validation data into two data sets, resampling methods such as cross-validation can be used. Finally, machine learning methods can be used to select the predictors and estimate their coefficients.
Applying predictive modeling for real-world evidence
Breast cancer subtypes offer a case study in leveraging modern statistical methods to help overcome limitations in administrative data. Distinct epidemiologic and clinical features of different types of breast cancer cannot be identified accurately in claims data using diagnosis codes that do not identify these subtypes. Historically, the possibility of researching diseases for which there were unspecific or no diagnosis codes has often been seen as an important or even insurmountable limitation of administrative databases. However, the distinguishing characteristics and natural histories of patients with these diseases presents an opportunity to use available codes to uncover patterns that help identify patients of interest.
HealthCore has used machine learning to develop predictive model algorithms in claims, including algorithms to define early and advanced stage ER+/HER2- breast cancer. This algorithm illustrates the application of machine learning methods to identify cases with clinical characteristics—stage and biomarker status—that are not coded granularly in claims.
For the breast cancer study, we first developed a conventional algorithm by collaborating with subject matter experts with knowledge of clinical coding practice. We then used the validation study to try to improve on our conventional algorithm. We describe below a step-by-step approach:
- Develop a screening algorithm that includes all or nearly all the cases of interest
- In our study, we included all patients with an ICD-9 or 10 diagnosis code for breast cancer. This strategy should identify nearly every case of ER+/HER2- breast cancer, but will include many false positive cases as well. Subsequent steps will enhance the specificity/PPV of the final algorithm.
- In our study, we included all patients with an ICD-9 or 10 diagnosis code for breast cancer. This strategy should identify nearly every case of ER+/HER2- breast cancer, but will include many false positive cases as well. Subsequent steps will enhance the specificity/PPV of the final algorithm.
- Identify a gold standard to use for the validation study
- HealthCore has clinical oncology data available for many patients including breast cancer stage and biomarker status. Such data can also be sought from medical records, cancer registries, or other provider-reported clinical sources.
- Identify candidate predictors
- We identified candidate predictors from diagnoses, procedures, and treatments from claims that could discriminate cases (e.g. advanced stage ER+/HER2- breast cancers) from non-cases (breast cancers without that specific profile). These hundreds of predictors were identified with subject matter experts and empirically by identifying the most common codes identified in cases and non-cases.
- Apply predictive modeling using machine learning or traditional regression approaches
- We used clinical oncology data to conduct supervised machine learning to develop predictive models for early and advanced stage ER+/HER2- breast cancer. We used Lasso logistic regression coupled with k-fold cross-validation to address potential overfitting. Other machine learning approaches can also be used. We used Lasso regression owing to its familiarity (similar in form to logistic regression) and ease of applying the model to other settings.
- Assess performance of predictive model algorithms
- A predictive model outputs the probability of being a confirmed case. The performance of the model (e.g. PPV and sensitivity) can be evaluated at various probability thresholds. Investigators can choose the specific threshold, depending on their needs, to best balance false negative and false positive errors in their study (as noted in the figure). In our study, we selected a threshold of 70% at which our predictive model improved both PPV (91% vs. 69%) and sensitivity (54% vs. 35%) compared with the conventional algorithm. A strength of this approach is that the threshold can be set by the investigator to suit the needs of a particular study. To measure the prevalence of an indication, for example, one might want a high sensitivity, then correct the prevalence for the PPV using quantitative bias analyses. In contrast, for etiologic research, researchers might seek a higher PPV.
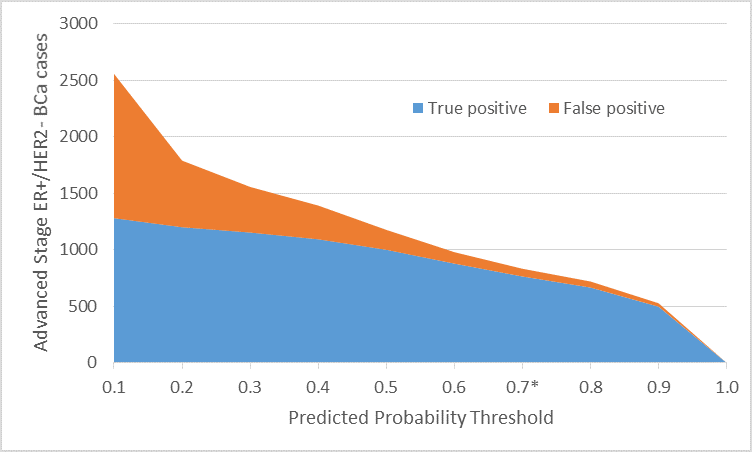
- Apply the predictive model algorithms to the large claims database to define cohorts
- We applied predictive model algorithms to a large claims database and increased the size of the cohorts, identifying 36,199 women with early or advanced stage ER+/HER2- breast cancer. The algorithm included predictors from claims, so it could be applied to other large claims databases (assuming generalizability across population).
Importance of predictive modeling for real-world evidence
Real-world evidence can usefully support precision medicine and faster regulatory approvals. The use of statistical methods to develop better case-identifying algorithms enables use of claims databases to study rare diseases and other targeted indications as well as more valid outcome ascertainment for safety and effectiveness research.
Further information on this work can be found in our publication of this study and in our recorded webinar: Identifying Medical Conditions in Administrative Claims Data: Validation and Machine Learning.





