Artificial Intelligence for Real-World Evidence
January 3, 2018
Costas Boussios, VP of Data Science, OM1
Richard Gliklich, CEO, OM1
As artificial intelligence (AI) and Big Data are lauded for their potential uses in life sciences and healthcare, it is becoming difficult to differentiate between the myriad of terms and technologies and their real value in advancing real-world evidence (RWE). In this article, we explore key AI and Big Data terms, their real-world application, and how they are building upon each other to transform our understanding of patient journeys and outcomes.
Big Data
Although Big Data is not required for artificial intelligence, much of the utility of AI comes from its application to large sets of information in the development of real world evidence. The term Big Data reportedly was first used by NASA engineers in the 1980’s who were trying to work with datasets that exceeded their ability to store and analyze them with traditional computing software. Since then, the emergence of the world wide web and the development of advanced computing machinery and software applications has resulted in an explosion of data-generating applications. Today, Big Data is bigger and more ubiquitous than ever before.
The need to store, secure, query, process, analyze and manage Big Data has led to the development of numerous technological innovations over the last 20 years. Earlier proprietary solutions, such as the Google Distributed Filesystem, have been succeeded by widely available open-source technologies, such as Apache Hadoop.
Furthermore, Cloud Computing solutions such as Amazon Web Services, Microsoft Azure and Google Cloud provide flexible, on-demand computing capabilities with the potential of minimizing IT capital and maintenance expenses for organizations of any size. The availability of free or flexible cost capabilities, thanks to the open-source community and to Cloud computing platforms as described above, have resulted in enhanced democratization of Big Data capabilities across industry sectors and budgets.
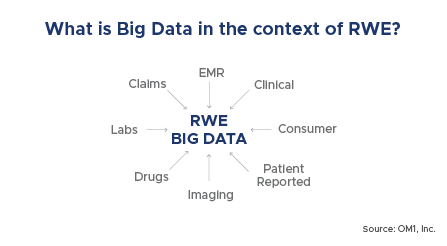
From a real-world evidence perspective, one of the main advantages of Big Data infrastructure is the ability to maintain very large, heterogeneous and linked data sets that are highly available, where they can be queried and statistically processed rapidly and can be used in visualizations on a near real-time basis. For example, not only can data be updated and added to existing visualizations such as for tracking the opioid epidemic on a real-time basis across the entire U.S., but even extremely large custom cohort studies, such as answering questions on lipid lowering therapy or type 2 diabetes, representing millions of people and billions of data points, can be accomplished in hours or days rather than months or years (if data needs to be collected). In addition, important AI implementations have been made easier thanks to increased integration of AI algorithms with Big Data software.
Natural Language Processing (NLP)
Natural language processing (NLP) is an AI tool that can be described as the ability of a computer program to understand the human language and automatically extract contextual meaning. NLP can be particularly useful in processing and evaluating large amounts of unstructured data. In healthcare, a common application is to evaluate physician notes in patient medical records, and find relevant information. By applying NLP, a system can more easily and rapidly extract and analyze data that would otherwise be too burdensome for researchers. NLP replaces the highly cumbersome act of medical chart extraction using teams of researchers.
NLP Techniques range from simple word-based models for text classification to rich, structured models for syntactic parsing, collocation finding, word sense disambiguation, and machine translation.
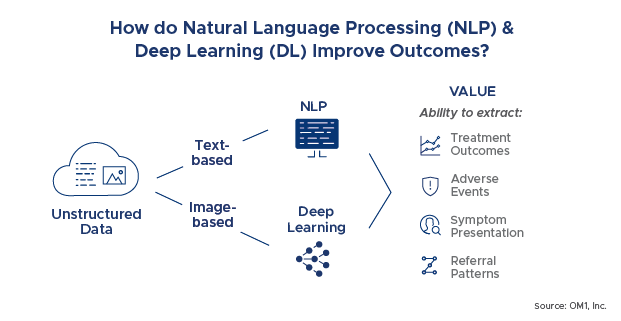
The NLP demand for real-world evidence is highly driven by the tremendous increase in textual unstructured clinical data. The practice patterns used by physicians for the documentation of clinical notes as well as patient discharge summaries have generated an enormous amount of unstructured data. Such voluminous data needs to be structured and analyzed effectively for enhanced reporting and analytics. NLP, combined with machine learning and deep learning as described below, is rapidly becoming accurate enough to automate or replace abstraction. This drives significant efficiencies in generating information from text for real world evidence purposes.
For example, NLP can be applied to find information on treatment outcomes, adverse events, symptom presentation and referral patterns. Consider the following physician notes examples:
“He states the symptoms are controlled. Less than 1% BSA currently affected.”
“Stopped [Drug X] d/c ‘increased depression.’ On Paxil but “feels not helping.” No psoriasis flares.”
“She has psoriasis on the back of her legs, torso, scalp. She uses a dermatologist. She was off [Drug X] for a URI and flared up.”
The underlined information are just examples of what is not captured in either billing or structured EMR data. The ‘old way’ would be to use nurse abstractors to chart review a small sample of patients. With advanced NLP, data on such things as reasons for discontinuation of a medication can now be captured at scale across tens of thousands of patients for less than the cost of a traditional chart review.

Machine Learning, Deep Learning and Cognitive Computing
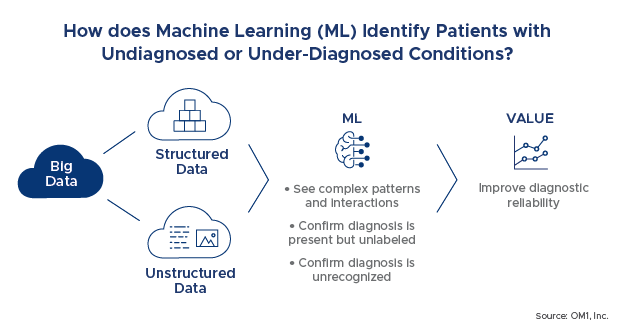
Machine Learning (ML) is a library of algorithms that scour over large volumes of data to accurately and efficiently learn relationships found in recorded examples. Over the last 15-20 years, ML has gradually been replacing traditional statistical inference as the tool of choice for learning complex relationships in data. The key advantage of ML is the capability to operate on large numbers of engineered predictive features in datasets including outliers, noise and collinearities, without the stability and reliability concerns of traditional statistical modeling. One of our key applications of this capability has been in identifying patients with undiagnosed or underdiagnosed conditions. For example, the current approach is to use coded billing information or prescriptions to identify patients. Using ML, we are able to see much more complex patterns and interactions that are similar between patients with and without a particular diagnosis and able to confirm that the diagnosis is present but either unlabeled (such as in dementia) or unrecognized (such as in early presentation of rare diseases like muscular dystrophy). This technology has the promise of improving diagnosis in the clinic as well as in research studies.
Deep learning is a newer generation of learning algorithms rooted in an older concept called neural networks. Neural networks use an array of nodes to perform computations or decisions rapidly. Deep learning can be thought of as stacking many neural networks. Deep learning has introduced the capability to effectively automate the generation of predictive features in various types of inference problems and thereby achieve breakthrough performance in applications such as image processing, speech recognition and language translation. In healthcare, some of the key applications of deep learning that are being pursued are for reading radiology exams or pathology slides.
Predictive vs Prescriptive Analytics
One of the most intriguing and potentially game changing examples of machine learning is in the area of predictive and prescriptive analytics. With traditional research approaches, evidence development focuses on evaluating and tracking what has already happened. But, how do we move from understanding what happened to being able to predict what will happen 6 months, a year, 5 years out?
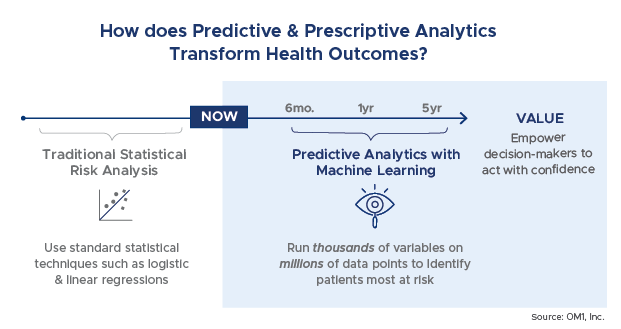
Using different mathematical techniques and modeling, predictive analytics use existing data to find trends and patterns and tell us what might happen. They help to identify who is most at risk and what outcomes can be expected.
Traditionally, risk analytics have been performed using standard statistical techniques such as stepwise logistic regression. In these approaches, characteristics or risks are identified and added into models to determine their impact on the model performance. While predictive analytics can be generated using traditional statistical approaches, ML enables models to be generated to include thousands of variables and millions of data points. The result is usually more highly performant models as well as the ability to uncover more data relationships of importance that might not have been considered to be so prior to the analysis.
For example, we recently presented a machine learning based model for predicting heart failure readmissions that outperformed existing models (LACE Risk Score) by 10 points[1] and relied on another machine learning based variable that measures the aggregate disease burden of a patient (OM1 Medical Burden Index (OMBI™)[2] and which is the strongest single predictor of many outcomes (heart failure admission and readmission, resource utilization).
Prescriptive analytics are an advanced form of predictive analytics. The goal of prescriptive analytics is to make the information presented actionable to a decision maker. Prescriptive analytics tell us what to do about the information that the predictive models generated and help us to know which ones matter most and what actions to take. For example, a clinician might use predictive analytics to understand who is most at risk for a cardiac event, whereas prescriptive analytics might tell the provider which patients have alterable factors, such as weight loss or smoking status, and which ones will have the greatest impact on outcomes.
As one can imagine, the healthcare and real-world evidence applications of these AI driven capabilities are potentially enormous. Clinicians are already using these capabilities to identify which patients are most likely to have poor clinical or financial outcomes and to proactively take actions to minimize that risk. For example, avoiding a cardiac readmission can save a health care payer or at-risk provider $14,000-$18,000 on average per event. The implications are similarly large for manufacturers. Predictive analytics are now being applied to identify patients most likely to benefit from certain treatments, those likely to be adherent to therapy, or even those likely to suffer an adverse event.
Conclusion
Artificial intelligence and big data are transforming real-world evidence from a largely retrospective viewpoint to a more concurrent and forward-looking set of capabilities. This paradigm shift also will drive RWE to the forefront of strategy for both healthcare and life sciences organizations. While there are many different components of AI that offer new approaches and methods to evaluating and generating real-world evidence, one common thread throughout is the importance of big data and the interdependency on having access to enormous amounts of data.
By embracing the innovation in AI (and the availability of big data), researchers can generate real-world evidence that is more dynamic, timely, representative, comprehensive and cost-effective. This next generation of real-world evidence will also have the ability to be used to measure, predict and personalize care in a way previously not possible. In the end, all healthcare stakeholders benefit when medical products and services are focused on and delivered to those who will benefit the most.
[1] Su Z , Brecht T , O’Donovan F , Boussios C , Menon V , Gliklich R , Fonarow GC. Machine Learning Enhanced Predictions of Hospital Readmission or Death in Heart Failure. AHA Scientific Sessions. November 11-15, 2017. Anaheim, CA.
[2] O’Donovan F, Brecht T, Kekeh C, Su Z, Boussios C, Menon V, Gliklich R, Fonarow G, Geffen D. Machine Learning Generated Risk Model to Predict Unplanned Hospital Admission in Heart Failure. AHA Scientific Sessions. November 11-15, 2017. Anaheim, CA.





